Abstract
A creative idea is often born from transforming, combining, and modifying ideas from existing visual examples capturing various concepts. However, one cannot simply copy the concept as a whole, and inspiration is achieved by examining certain aspects of the concept. Hence, it is often necessary to separate a concept into different aspects to provide new perspectives. In this paper, we propose a method to decompose a visual concept, represented as a set of images, into different visual aspects encoded in a hierarchical tree structure. We utilize large vision-language models and their rich latent space for concept decomposition and generation. Each node in the tree represents a sub-concept using a learned vector embedding injected into the latent space of a pretrained text-to-image model. We use a set of regularizations to guide the optimization of the embedding vectors encoded in the nodes to follow the hierarchical structure of the tree. Our method allows to explore and discover new concepts derived from the original one. The tree provides the possibility of endless visual sampling at each node, allowing the user to explore the hidden sub-concepts of the object of interest. The learned aspects in each node can be combined within and across trees to create new visual ideas, and can be used in natural language sentences to apply such aspects to new designs.
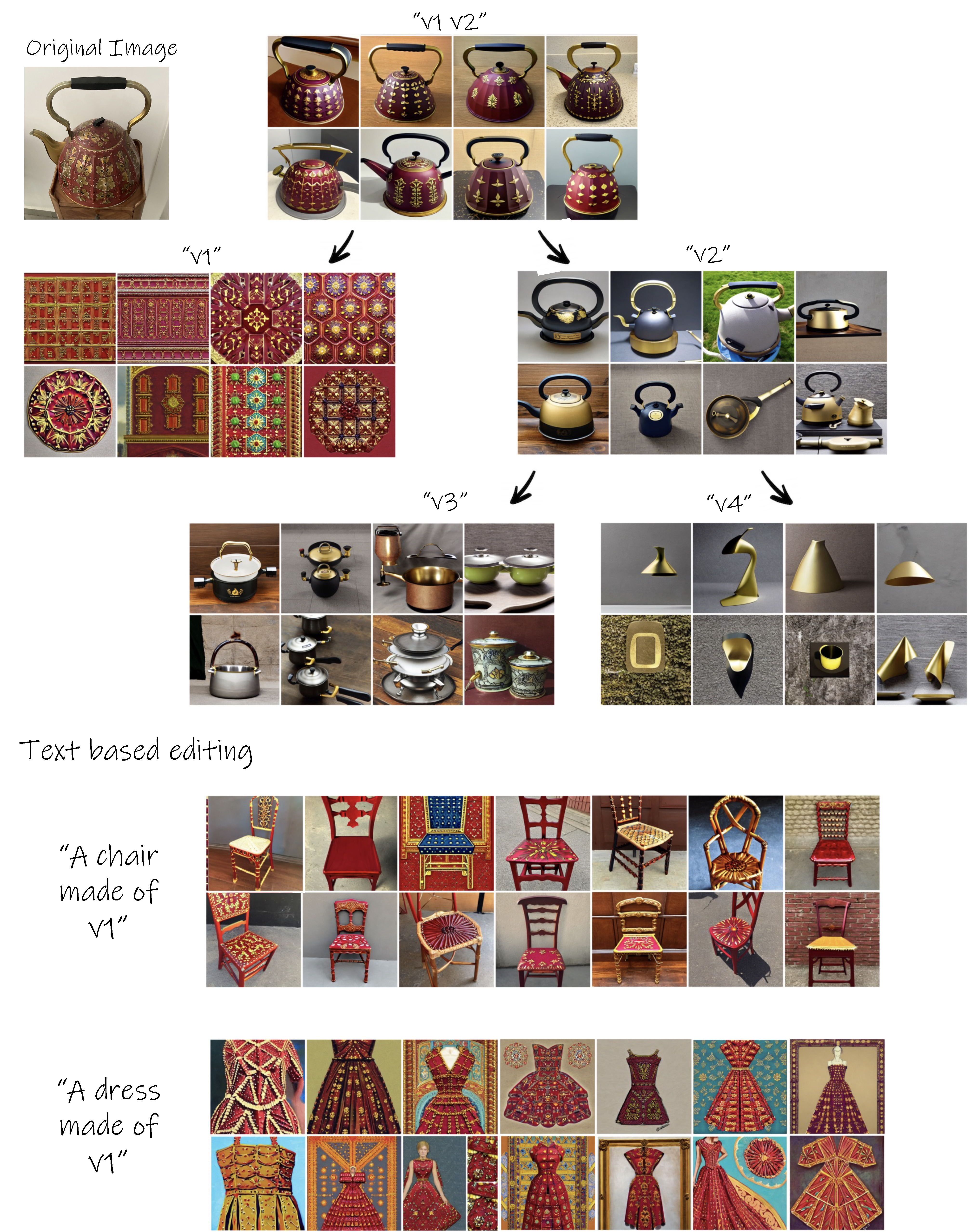
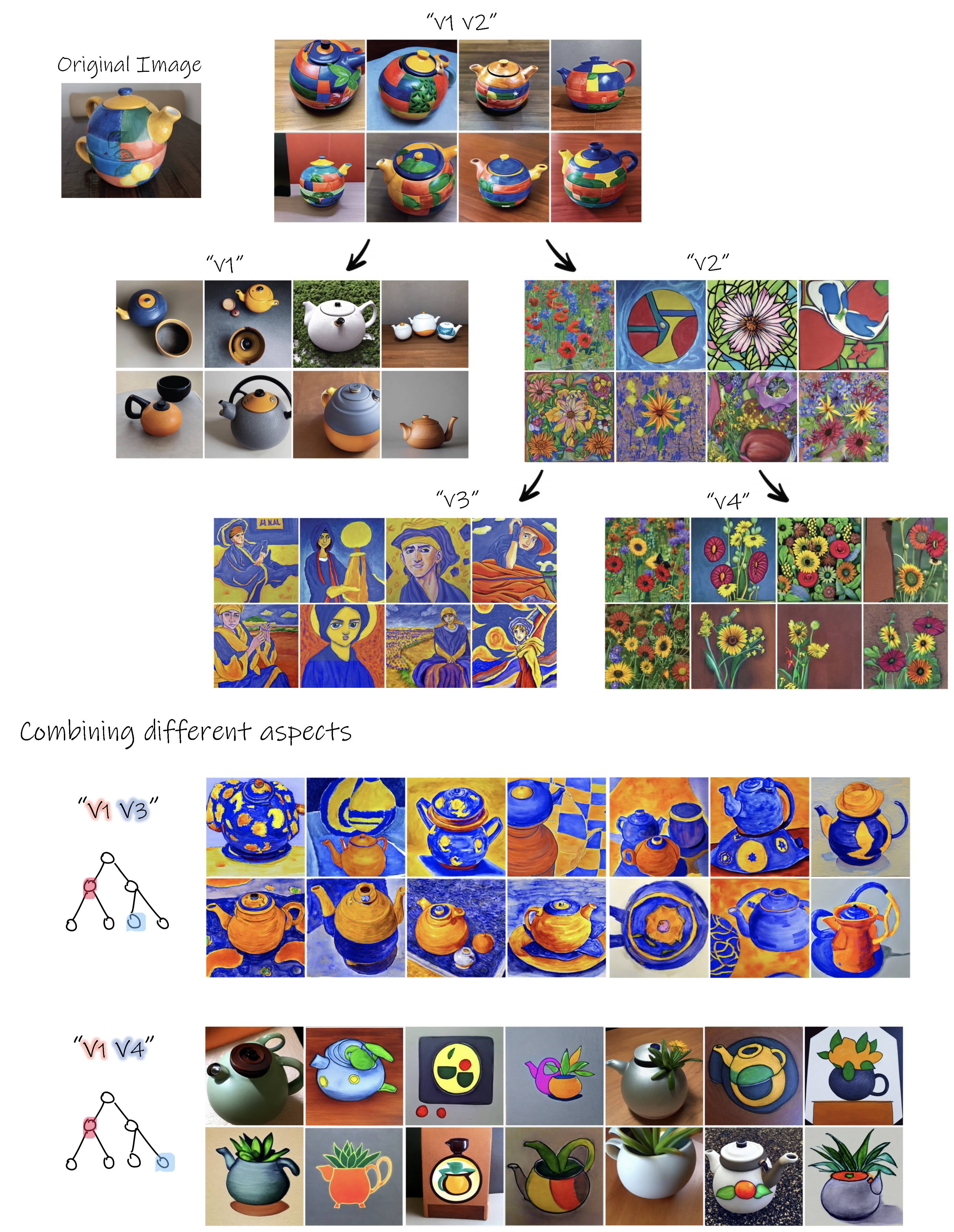
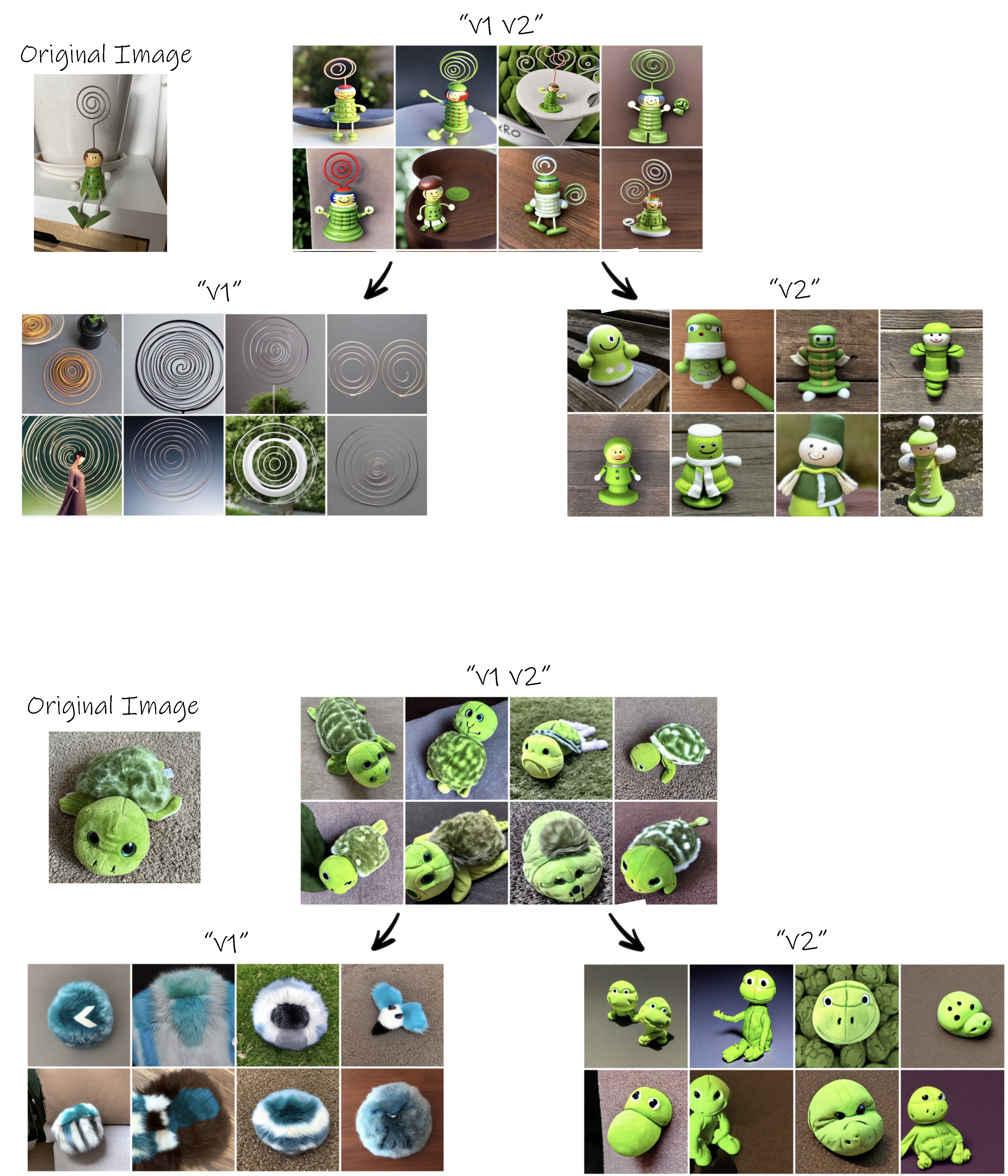
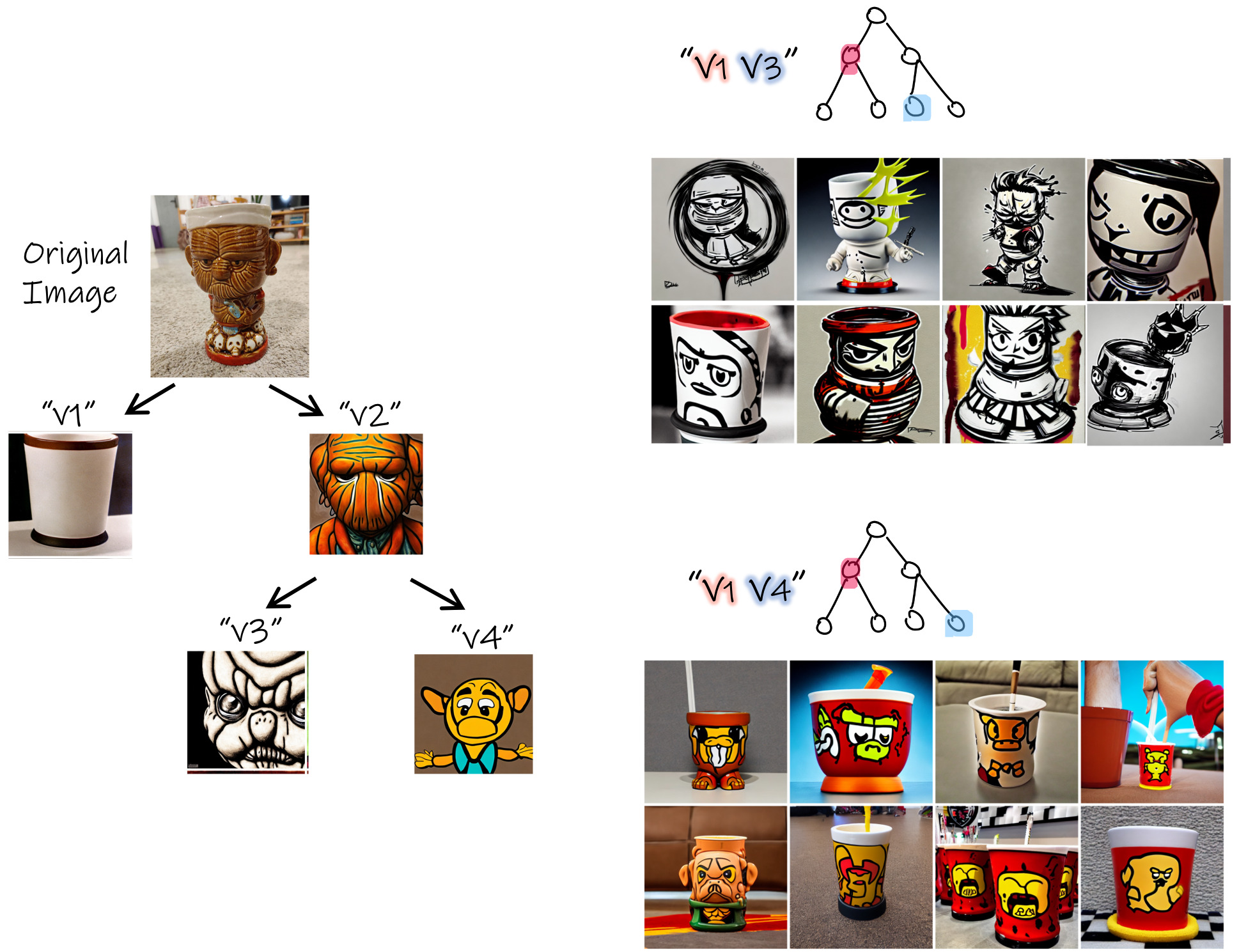
Examples of exploration trees 






How does it work?
Given a small set of images depicting the desired visual concept, our goal is to construct a rich visual exploration space expressing different aspects of the input concept. We model the exploration space as a binary tree, whose nodes are learned vector embeddings corresponding to newly discovered words added to the predefined dictionary, representing different aspects of the original concept. The exploration tree is built gradually as a binary tree from top to bottom, where we iteratively add two new nodes at a time.
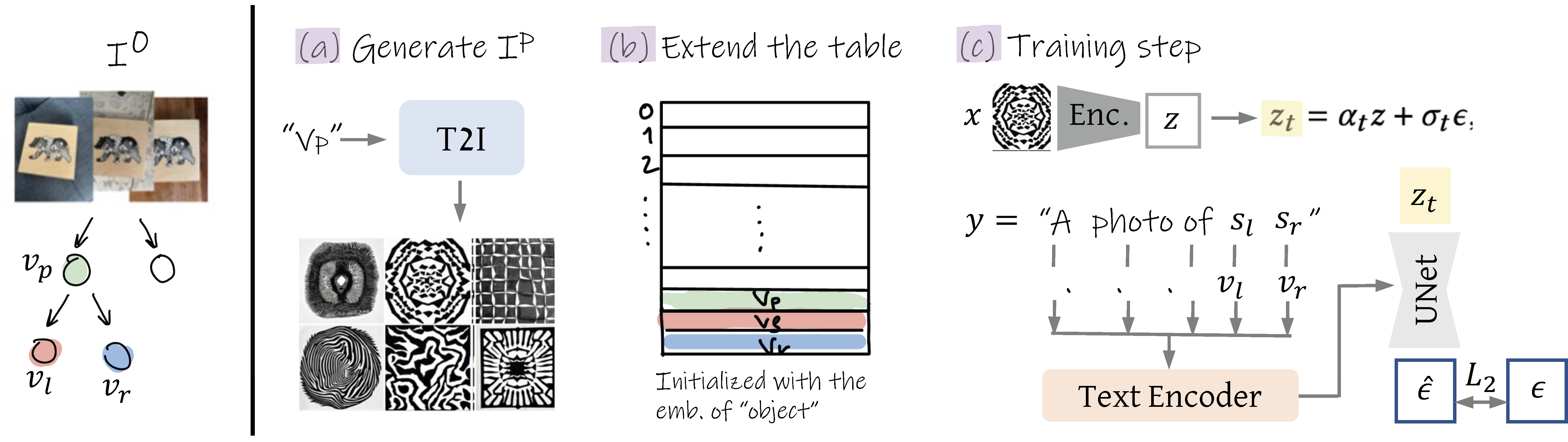
To create two child nodes, we optimize new embedding vectors according to the input image-set generated from the concept depicted in the parent node.
During construction, we define two requirements to encourage the learned embeddings to follow the tree structure:
(1) Binary Reconstruction each pair of children nodes together should encapsulate the concept depicted by their parent node, and (2) Coherency each individual node should depict a coherent concept which is distinct from its sibling. Next, we describe the loss functions and procedures designed to follow these requirements.
The constructed tree provides a rich visual exploration space for concepts related to the object of interest.
We next demonstrate how this space can be used for novel combination and exploration.
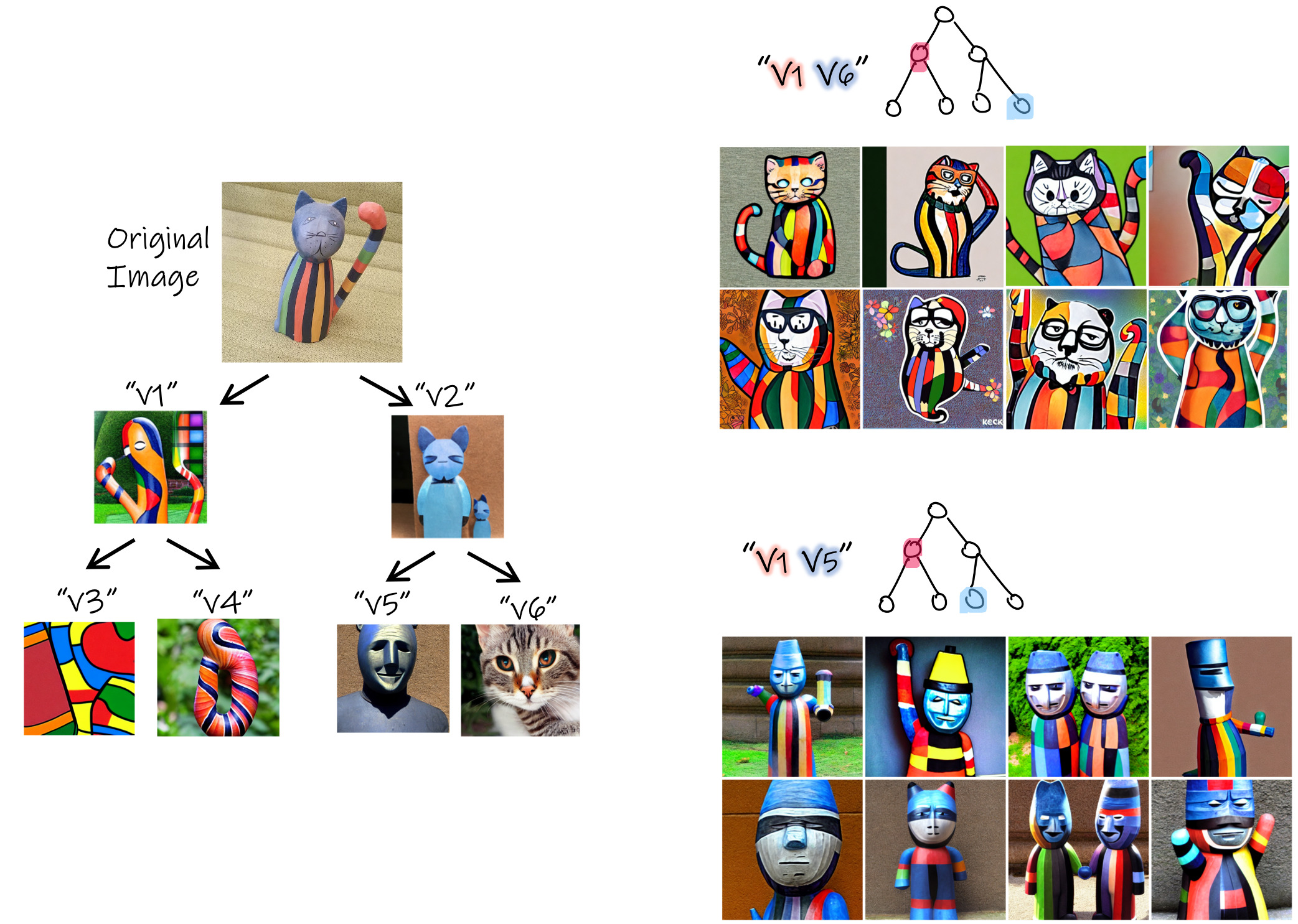
1. Intra-tree combination
We can explore combinations of different aspects by composing sentences containing different subsets of the nodes. For example, below we have combined "v1" and "v5", which resulted in a variation of the original sculpture without the sub-concept relating to the cat (depicted in "v6"). At the bottom right, we have excluded the sub-concept depicted in "v5" (related to a blue sculpture), which resulted in a new representation of a flat cat with the body and texture of the original object.

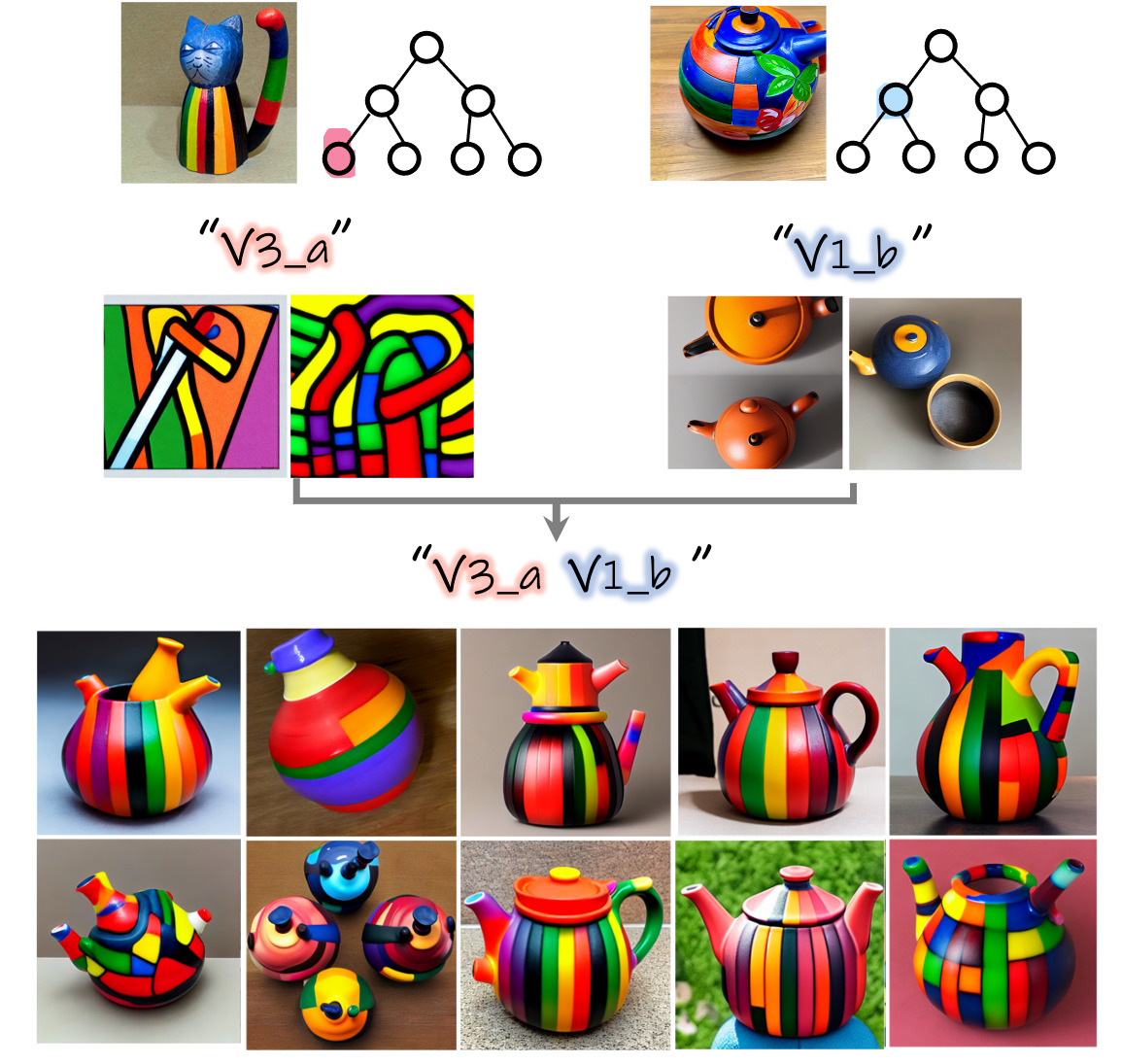
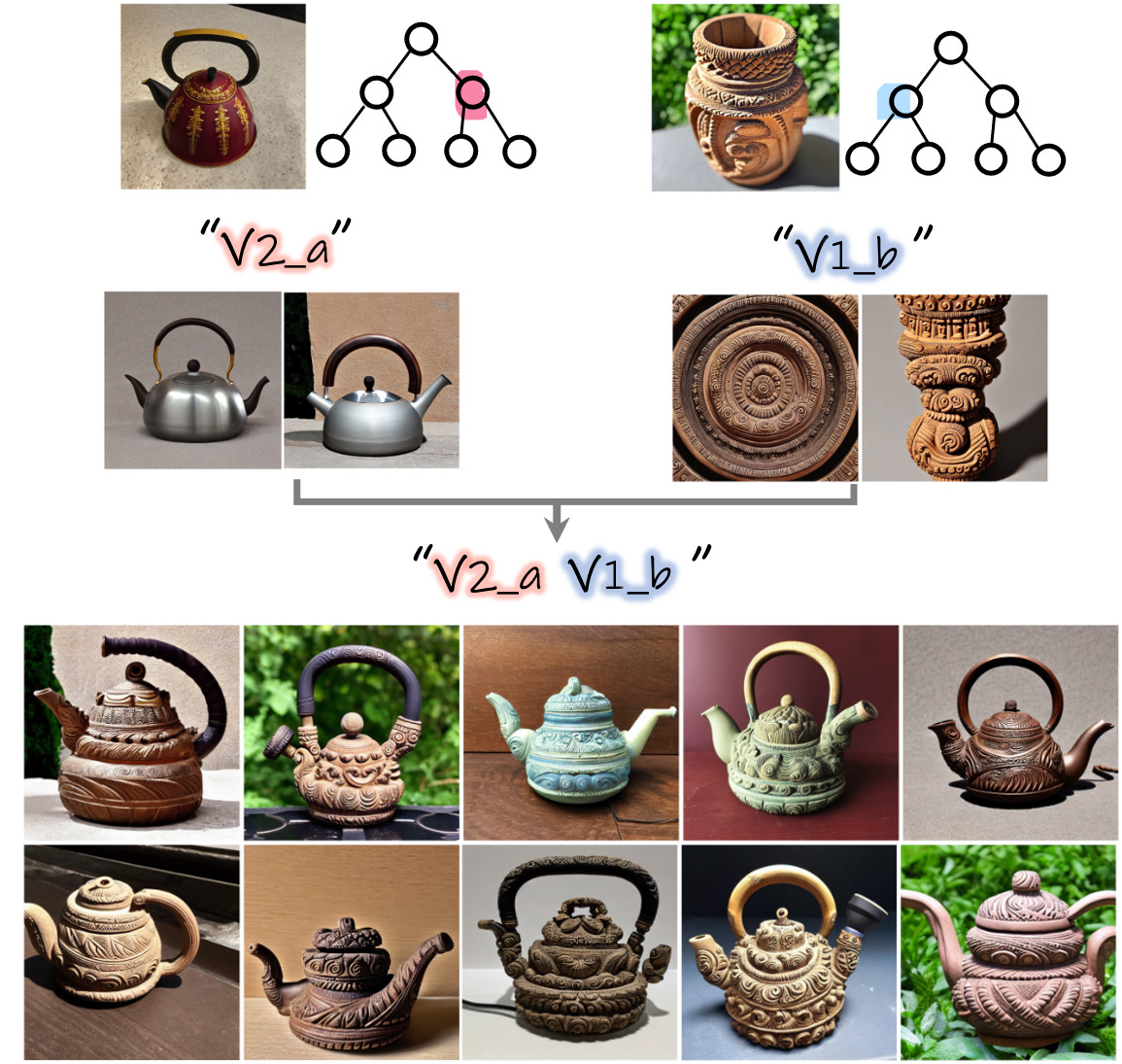
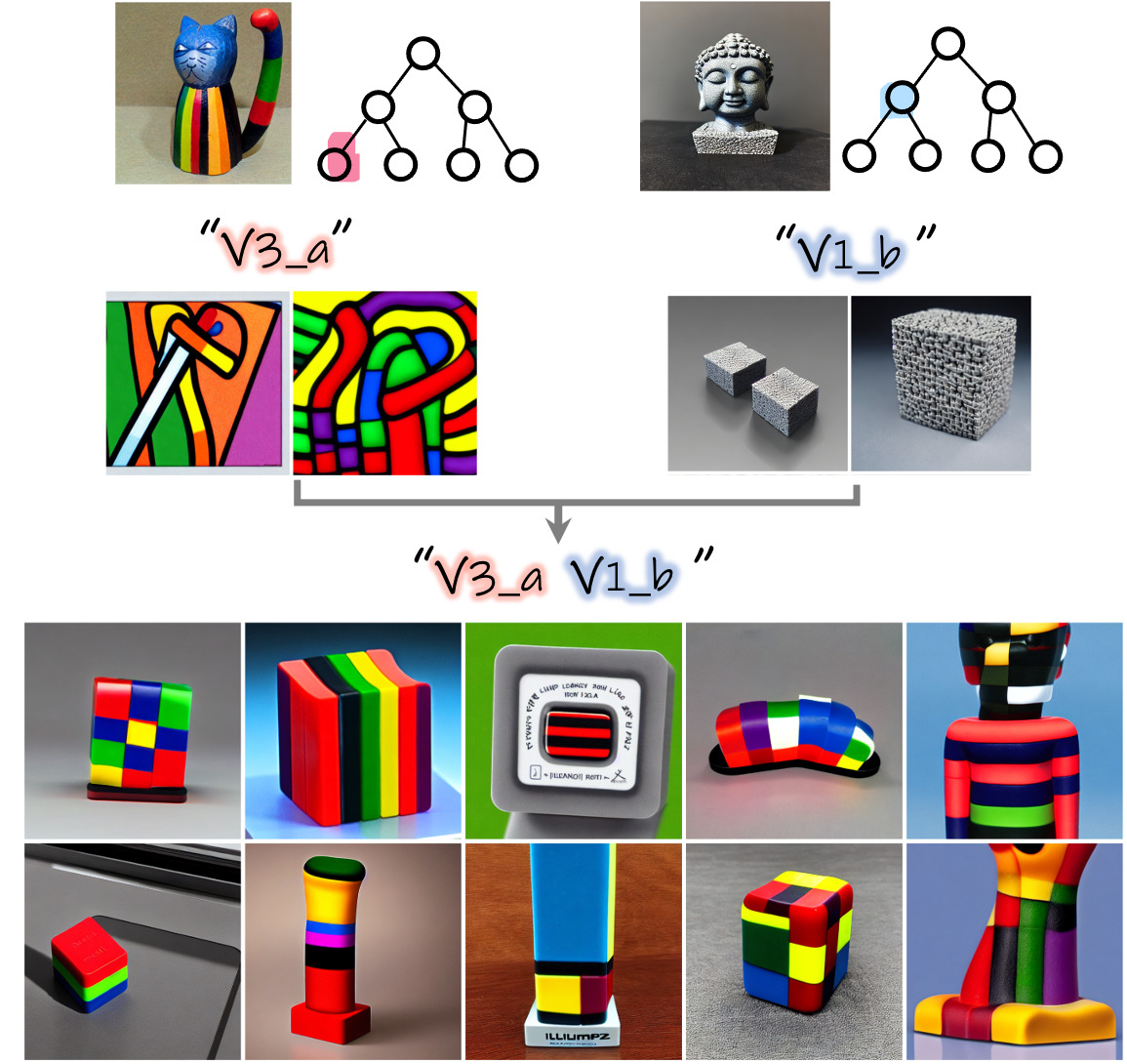
2. Inter-tree combination
It is also possible to combine concepts learned across different trees. To achieve this, we first build the trees independently for each concept and then visualize the sub-concepts depicted in the nodes to select interesting combinations. We demonstrate this below:



3. Text-based generation
The placeholder words of the learned embeddings can be composed into natural language sentences to generate various scenes based on the learned aspects.







BibTeX
@misc{vinker2023concept,
title={CConcept Decomposition for Visual Exploration and Inspiration},
author={Yael Vinker and Andrey Voynov and Daniel Cohen-Or and Ariel Shamir},
year={2023},
eprint={2305.18203},
archivePrefix={arXiv},
primaryClass={cs.CV}
}